Distributed Data Science using NVTabular on Spark & DaskNVTabular — Why, What, and How?Feb 18, 2022Feb 18, 2022
Too Small Data — Solving Small Files issue using SparkI am pretty sure you all must have come across the issue of Small files issues while working with Big Data frameworks like Spark, Hive etc.Dec 25, 20201Dec 25, 20201
Published inDataDrivenInvestorData Masking in Big Data [Spark]We often face challenges over masking data in our Big Data pipelines so that all sensitive data is masked from the unauthorized users…Aug 8, 20191Aug 8, 20191
Published inDataDrivenInvestorHandling complexity in Big Data — Process nested json with changing schema tagsYou may have seen various cases of reading json data ranging from nested structure to json having corrupt structure. But, lets see how do…Nov 3, 20183Nov 3, 20183
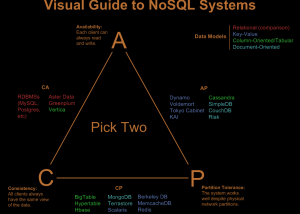
NoSQL SimplifiedBasics of NoSQL NoSQL eliminates the need of a schema, hence pushing the data handling capacity by a huge margin by compromising on ACID…Sep 22, 2018Sep 22, 2018


![Data Masking in Big Data [Spark]](https://miro.medium.com/v2/resize:fill:160:106/1*WZcM4yBSBaoMdBDKNNJMJw.png)
![Data Masking in Big Data [Spark]](https://miro.medium.com/v2/resize:fill:320:214/1*WZcM4yBSBaoMdBDKNNJMJw.png)